MSteineke
Over the last few months I have run into similar configuration problems at a number of places. After the 4th or 5th time seeing the same issue I thought it deserved a blog post… Especially after I realized that I have also been making the same mistake on some of my own systems.
Block size is very important for performance for a number of server functions, particularly SQL server. There is a best practice article written in 2009 by Jimmy May and Denny Lee from Microsoft SQL CAT (Now Azure CAT). http://technet.microsoft.com/en-us/library/dd758814(v=SQL.100).aspx Jimmy also updated his blog a few months ago reiterating how important this still is for the current versions of SQL. http://blogs.msdn.com/b/jimmymay/archive/2014/03/14/disk-partition-alignment-for-windows-server-2012-sql-server-2012-and-sql-server-2014.aspx
I’m sure a few of you are thinking, yes we have been doing this for a long time, we know best practice is to use 64k block for SQL. How many of you are virtualizing your SQL Servers? So you make your VHDx and format it with a 64k block. You’re good right? Maybe not. If you are putting those VHDx files on a Cluster Shared Volume on your Hyper-V cluster, what is that physical volume’s block size?
So for those that don’t know how to check this, all you need to do is run CHKDSK (from an elevated command prompt) to check the block size. If you go run this you will probably end up with something like I have here on my workstation. Where the block size default is 4096 bytes.

To make this work with a CSV volume, since it does not have a drive letter the syntax is: chkdsk.exe <CSV mount point name> http://blogs.msdn.com/b/clustering/archive/2014/01/02/10486462.aspx
I thought that there also had to be some PowerShell to help with this, and iterate through all the CSV volumes on the cluster, because there are probably more than one of them right. I searched for a while and came up with a bunch of articles on how to check free space on the CSV, which is useful, but nothing that said what the block size was. So I then reached out to my friend and PowerShell MVP Steven Murawski for some help. About 4 minutes later he sent me some PowerShell to help with my problem:
$ComputerName = '.'
$wql = "SELECT Label, Blocksize, Name FROM Win32_Volume WHERE FileSystem='NTFS'"
Get-WmiObject -Query $wql -ComputerName $ComputerName | Select-Object Label, Blocksize, Name
This was almost exactly what I wanted, but it did not show me the block size for the CSV volumes, but it did for all the NTFS volumes. CSV volumes, while they may have started as NTFS, when they are converted to a CSV, the format is referred to as CSVFS, so with a little tweak to what he gave me:
$ComputerName = '.'
$wql = "SELECT Label, Blocksize, Name FROM Win32_Volume WHERE FileSystem='CSVFS'"
Get-WmiObject -Query $wql -ComputerName $ComputerName | Select-Object Label, Blocksize, Name
Now this will list all the CSV volumes in a cluster and their Block Size.

So now that I can easily check that block size, what do I really want it to be? Well for SQL Server you want it to be the same best practice of 64k. For other workload this seems to be the size that makes sense to use as well. There are a lot of articles out there for specific hardware, and what is best for them. There is no Best Practice for Hyper-V that I have found from Microsoft, there are a lot of comments on what to use, and they all point to using 64k as the volumes are usually RAID. That said if you read all of the article Jimmy and Denny wrote, it states:
“An appropriate value for most installations should be 65,536 bytes (that is, 64 KB) for partitions on which SQL Server data or log files reside. In many cases, this is the same size for Analysis Services data or log files, but there are times where 32 KB provides better performance. To determine the right size, you will need to do performance testing with your workload comparing the two different block sizes.”
Keeping this in mind you may need to have volumes that are formatted with different block sizes for specific workloads. You will need to test your specific IO scenario if you want to optimize the system. And you should make sure that at all levels you are using the best block size for your workload. For those who don’t know how to check IO workload, one popular tool you can use is SQLIO. http://www.microsoft.com/en-us/download/details.aspx?id=20163
MSteineke
 I am speaking with Microsoft at the 2014 Dell Users Forum in Florida. http://www.dellenterpriseforum.net/information.php The event is located Ocean side at the Westin Diplomat Resort & Spa. I can't wait to check out the event!
I am speaking with Microsoft at the 2014 Dell Users Forum in Florida. http://www.dellenterpriseforum.net/information.php The event is located Ocean side at the Westin Diplomat Resort & Spa. I can't wait to check out the event!
MSteineke
There are a few ways you can configure MSDTC when you need to use it on a SQL Fail over Cluster Instance. We have applications that need to commit transactions across multiple SQL FCIs so a Clustered DTC is necessary. If you only have 1 active SQL node, it is pretty easy, you create a clustered DTC, which lives as its own clustered Application.
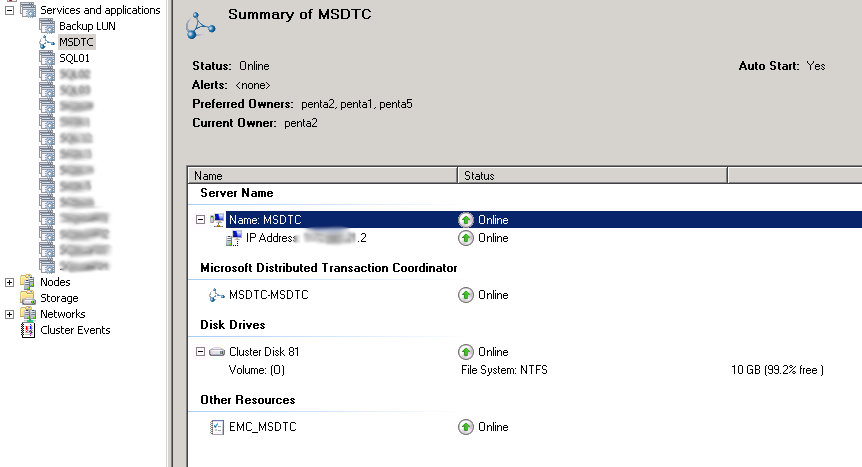
As you can see MSDTC has an IP resource, a name resource and a Disk resource in the cluster, and the disk resource is mounted as a drive letter.
Although there are a few ways that are supposed to work to create multiple MS DTC instances in a cluster, there is only one that I have found to work reliably. That way is to create an MSDTC service inside each SQL application.
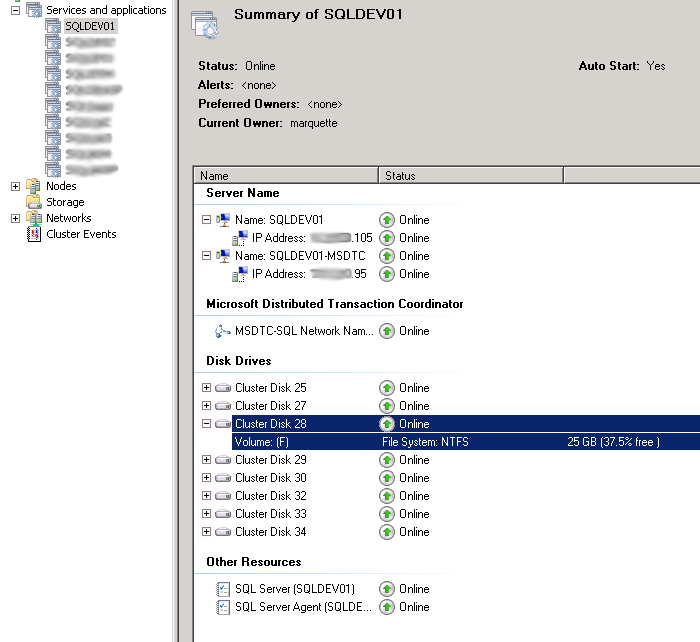
As you can see above there are all the same resources that are in a single clustered MSDTC, with a few modifications. I have shared the Drive Volume F with the SQL System databases, to not waste another drive letter, since SQL needs to use one anyway. You need to make sure that you have enough space to hold the databases and DTC. In our configurations we also move TempDB to another LUN, by default it would be in this location and it would be easy to run out of disk. I have also added a dependency for the SQL Service on the MSDTC Service to ensure that the MSDTC instance is running before SQL starts. SQL will then always pick the MSDTC that is running in the same cluster application. I have found to make this work, you must have a unique name and IP for each MSDTC contrary to documentation that says you can share a name and IP.
MSteineke
Talked to a lot of people at TechEd NA about SQL Server 2012, and AlwaysOn. Quite a few in the Intel booth with my demo on an NEC 1080aGX, and in the SQL Server High Availbility TLC Area. I hope the attendees at TechEd Europe next week like the video in the Intel booth, since I won't be able to be there myself.
MSteineke
10:15 Eastern - DBI315 - SQLCAT: HA/DR Customer Panel - Microsoft SQL Server 2012 AlwaysOn Deployment Considerations
Come check out all of the implementation details from customers on SQL 2012 AlwaysOn!